|
|
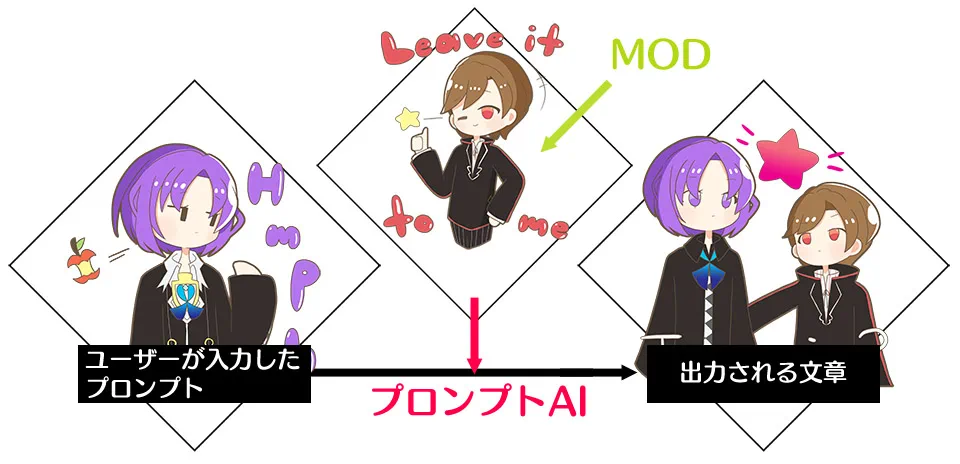
Japanese Storywriting AI |
|
|
Japanese Storywriting AI |

Tag Lucille
Description
@range 400
@priority 5
[Lucille: I. A white cat with pure white fur]

| First Language | Japanese |
| Second Language | English, Korean, Simplified Chinese, Traditional Chinese |
| Third Language | French, German, Spanish, Portugese |
| Sequence length | 32768 |
| Other | Self-proclaimed private eye |

| First Language | Japanese |
| Second Language | English, Korean, Simplified Chinese, Traditional Chinese |
| Third Language | French, German, Spanish, Portugese |
| Sequence length | 32768 |
| Other | Self-proclaimed private eye |

| Language | Japanese |
| Effective size of the corpus | 約3TB |
| Tokenizer | Trinsama-tokenizer V3 |
| Maximum sequence length | 16384トークン |
| Number of parameters | - |
| MOD | Not supported |
| Other | Chaser Maiden |

| Language | Japanese |
| Effective size of the corpus | 2.5TB |
| Tokenizer | Trinsama-tokenizer V3 |
| Maximum sequence length | 9216 tokens (depending on the active membership) |
| Number of parameters | - |
| MOD | Not supported |
| Other | Spherical Deity |

| Language | Japanese |
| Parameters | 7.3 billion |
| Effective size of the corpus | 1.2TB + 1GB |
| Tokenizer | Trinsama-tokenizer |
| Sequence length | 2048 tokens (depending on the active membership) |
| Attention heads | 16 |
| MOD | × |
| Other | Ghost-kei girl |

| Language | Japanese |
| Parameters | 20 billion |
| Effective size of the corpus | 2TB |
| Tokenizer | Trinsama-tokenizer V3 |
| Sequence length | 3076 tokens (depending on the active membership) |
| Attention heads | 60 |
| MOD | × |
| Other | Chaser Damsel |

| Language | English |
| Parameters | 13 billion / 20 billion |
| Effective size of the corpus | Up to 1.2TB |
| Tokenizer | GPT-2 Tokenizer(13B) Pile Tokenizer(20B) |
| Sequence length | 2048 tokens |
| MOD | × |
| Other | Mathematician |
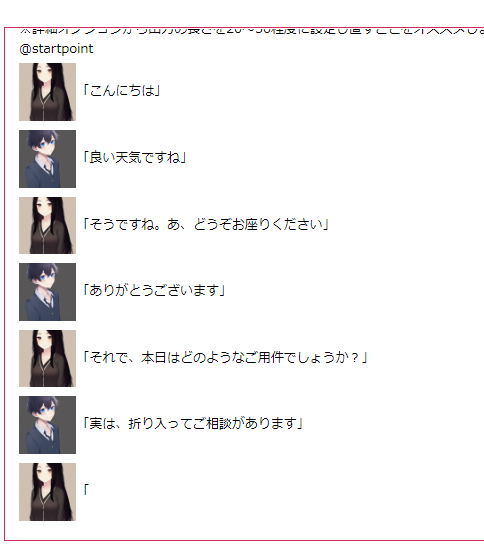


"Novel" mode is the default setting for AI Novelist and has features specialized for novels.
Enter text in the text area and press the "Continue Writing" button to send the text, and the AI will generate text according to the content.
In "Novel" mode, the following shortcuts can be used in addition to entering and editing text.
・Ctrl+Enter key
Sends the currently entered text to the AI.
This has the same function as the "Continue Writing" button.
・Ctrl+R key
Deletes the text returned by the AI in "Continue Writing" and tries to generate again with the text before the AI responded.
This shortcut has the same function as the "Retry" button.
・Ctrl+Q key
Returns to the previous text returned by the AI. If you pressed "Continue Writing", it will return one step, and if you pressed "Retry" or Ctrl+R, it will return the number of times you retried.
This shortcut has the same function as the "Undo" button.
・Ctrl+Shift+Q key
Restores the text that was undone with "Undo". It can be restored only as many times as it was undone with "Undo".
This shortcut has the same function as the "Redo" button.
・Ctrl+1 to 3 keys
Changes the current writing mode.

Unlike "Novel" mode, "Chat/Game" mode has its own operation methods.
・Enter key in the input field
Adds the entered utterance content to the main text area and sends it to the AI.
・Shift + Enter key in the input field
Inserts a line break in the input field. If you want to send multiple lines, you can insert a line break by pressing Shift+Enter.
As a supplement, since there is no writing mode in "Chat/Game" mode, the shortcuts for switching writing modes, Ctrl+1 to 3, are all disabled only in this mode.
(* The writing mode is basically fixed to "Default".)
The input field is basically designed to "not automatically add a line break if the closing quotation mark is not closed", but there are exceptions depending on the input content.
If multiple quotation marks are used, each quotation mark has a priority, and if a quotation mark with higher priority is closed, an automatic line break will be added even if other quotation marks are not closed.
The priority settings are as follows.
・High priority
「」 Quotation Marks
・Medium priority
『』 Double Quotation Marks
【】 Black Lenticular Brackets
() Parentheses
<> Angle Brackets
・Low priority
《》 Double Angle Brackets
{} Curly Brackets
[] Square Brackets
For example, even if a double quotation mark (『』) is not closed within a quotation mark (「」), if the quotation mark is already closed, an automatic line break will be added.

